Machine Learning Algorithms for Property Price Prediction
Geographic location remains a paramount factor in determining property value. Proximity to amenities like schools, hospitals, and parks, as well as access to transportation networks, significantly influences desirability and thus, property prices. Neighborhood character, including crime rates and the overall quality of life, also plays a crucial role. A safe and vibrant community with easy access to essential services typically commands higher property valuations compared to areas with less desirable characteristics. Understanding these geographical factors is vital for accurate property value predictions.
Furthermore, the presence of natural features, like scenic views or proximity to bodies of water, can enhance property value. These features can attract buyers seeking particular lifestyle preferences, leading to increased competition and higher prices. Conversely, proximity to industrial areas or undesirable environmental conditions can negatively impact property values.
Market Trends and Economic Conditions
The overall real estate market, driven by economic conditions, significantly impacts property values. Periods of economic growth often see increased demand for housing, leading to higher prices. Conversely, economic downturns typically result in decreased demand and lower property values. Factors like interest rates, inflation, and unemployment rates all play a crucial part in shaping market trends.
Understanding these broader economic trends is essential for accurately forecasting property value changes. Changes in employment opportunities, shifts in population demographics, and the availability of financing options all contribute to the dynamics of the market. A thorough analysis of these factors is essential for informed property valuation.
Building Characteristics and Condition
The physical attributes of a property, such as size, age, and condition, are crucial determinants of its value. Larger properties, particularly those with multiple bedrooms and bathrooms, generally command higher prices. The age of the structure, along with its structural integrity and the quality of its construction, are important considerations. Modern, well-maintained homes typically fetch higher prices than older properties that require significant renovations.
Features like updated kitchens and bathrooms, modern appliances, and energy-efficient systems can also significantly increase a property's value. Conversely, properties with outdated features or significant maintenance needs will command lower prices. A detailed assessment of building characteristics is essential for accurate property valuation.
Property Features and Amenities
Beyond basic building characteristics, specific amenities and features contribute to a property's appeal and value. A swimming pool, a private garden, or a spacious yard can significantly enhance a property's desirability, leading to higher prices. Proximity to desirable amenities like shopping centers, restaurants, and entertainment venues can also boost property value.
Supply and Demand Dynamics
The interplay between supply and demand in the local real estate market is a critical factor in determining property value. When demand exceeds supply, prices tend to rise. Conversely, an oversupply of properties in relation to demand often leads to lower prices. Factors like population growth, migration patterns, and new construction activity all influence this dynamic.
Analyzing historical sales data, current listings, and projected future trends can help assess the balance between supply and demand. Understanding this dynamic is critical for accurately predicting future property values.
Influence of Local Regulations and Policies
Local zoning regulations, building codes, and other policies can significantly affect property values. Restrictions on building density, setbacks, or specific types of development can impact the potential for future development and resale value. Environmental regulations, such as conservation easements or flood zones, can also influence pricing. A comprehensive understanding of local policies is crucial when evaluating a property's potential.
Understanding the implications of these policies is essential to accurately assess the long-term value of a property. Changes in these regulations can have a substantial impact on property values, so staying abreast of local policy changes is important.
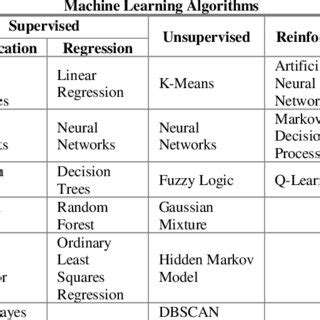
Data Preprocessing and Feature Engineering for Enhanced Accuracy
Data Cleaning and Transformation
Data preprocessing is a crucial step in any machine learning project, as the quality and format of the input data directly impact the model's performance. Cleaning involves handling missing values, outliers, and inconsistencies within the dataset. This might entail imputation of missing values using techniques like mean, median, or more sophisticated methods like K-Nearest Neighbors. Outlier detection and removal is also essential to prevent these extreme values from skewing the model's learning process. Data transformation, such as normalization or standardization, is often necessary to ensure that features have comparable scales, which can significantly improve the performance of algorithms like k-Nearest Neighbors, Support Vector Machines, and many others. Proper handling of these aspects lays the foundation for accurate model training.
Furthermore, data transformation techniques like log transformations or square root transformations can be applied to address skewed distributions. This process not only improves the model's efficiency but also enhances its ability to accurately capture underlying relationships within the data. In essence, meticulous data cleaning and transformation are fundamental to achieving optimal machine learning model accuracy, as they ensure that the model is trained on reliable and well-prepared data.
Feature Selection and Engineering
Feature selection involves identifying the most relevant features from the dataset for training the machine learning model. This process is vital because irrelevant or redundant features can negatively impact model accuracy and efficiency. Methods like correlation analysis, recursive feature elimination, and filter methods are frequently used to identify important features, reducing the dimensionality of the dataset without compromising crucial information. Such techniques are critical in preventing overfitting and improving model generalization capabilities. This meticulous process ensures that the model focuses on the truly informative aspects of the data, leading to enhanced predictive power.
Feature engineering involves creating new features from existing ones to improve model performance. This can involve combining existing features, extracting relevant information from text or image data, or applying domain expertise to create features that capture nuances not directly present in the original data. For instance, in a dataset containing customer purchase history, creating features like average purchase frequency or total spending over time can provide valuable insights and potentially enhance the accuracy of a model predicting future purchases. By crafting informative new features, we equip the model with a richer understanding of the data, ultimately leading to better predictions.
Handling Categorical Data and Imbalanced Datasets
Machine learning models often require numerical data, but real-world datasets frequently contain categorical variables. These variables need to be encoded into numerical representations to be utilized by the model. Techniques like one-hot encoding or label encoding are common methods for handling categorical features. Proper encoding ensures that categorical information is incorporated effectively into the model's learning process, maintaining the integrity and accuracy of the results. Failure to address categorical data can lead to inaccurate model predictions and significant loss in model performance.
Another crucial aspect is dealing with imbalanced datasets, where one class significantly outnumbers others. This can lead to biased models that favor the majority class. Addressing this requires techniques like oversampling the minority class, undersampling the majority class, or using cost-sensitive learning algorithms. Applying these methods to ensure balanced representation of all classes is essential for building models that can accurately predict even less frequent events, leading to a more comprehensive and robust machine learning solution. Careful consideration of these factors is crucial for the creation of accurate and reliable machine learning models.
Read more about Machine Learning Algorithms for Property Price Prediction